Deciphering Cloud-Native
- Senthil kumar
- Jul 23, 2021
- 37 min read

What is Cloud-Native is all about?
The cloud-native dive straight into technology choices of containerization and microservices. These are potential ingredients of a cloud-native project, but they are most certainly not the whole picture. Across this article, we will explore cloud-native from several different angles across this article, including technology and infrastructure, of course, and architecture, design, and perhaps most overlooked people and processes. I have put in the simplest possible terms, cloud-native means not just moving to the cloud but fully leveraging the uniqueness of cloud infrastructure and services to rapidly deliver business value.
Cloud-native concepts existed even before the term itself came into use. In a sense, cloud-native began when public cloud vendors started providing accessible and affordable access to elastic instances of computing power. The question then became, how can you write applications to capitalize on the flexibility of this new infrastructure, and what business benefits can you achieve as a value?
Cloud-native methods and technology have changed a lot over a decade. They are still evolving, but the core technical and business objectives that cloud-native applications set out to achieve have remained. These include:
Agility and Productivity: Enable rapid innovation business metrics directs those. De-risk maintenance and keep environments current.
Resilience and Scalability: Target continuous availability that is self-healing and downtime-free. Provide elastic scaling and the perception of limitless capacity.
Optimization and Efficiency: Optimize the costs of infrastructural and human resources. Enable free movement between locations and providers.
We will break these goals down more in a later article when we look back at the “why” of cloud-native, but hopefully, even from this simplistic definition, it should be clear that cloud-native is broader than simply a move to a new type of infrastructure. However, while these goals are accurate, it’s hard to see they apply to cloud-native specifically. We need to do more to define what cloud-native means.
Popular reference points related to cloud-native, such microservices, and older manifestos such as 12factor apps might lead you to conclude that cloud-native is a description of an architectural style, and the other choices follow from that. There is undoubtedly some truth in that and cloud-native architectures do exist. However, to succeed with cloud-native, the enterprise must take a more holistic view. Alongside architectural and infrastructural decisions, there are also organizational and process decisions. That has led us to a critical realization:
Technology alone cannot attain business outcomes.
The diagram below shows how these decisions interact.
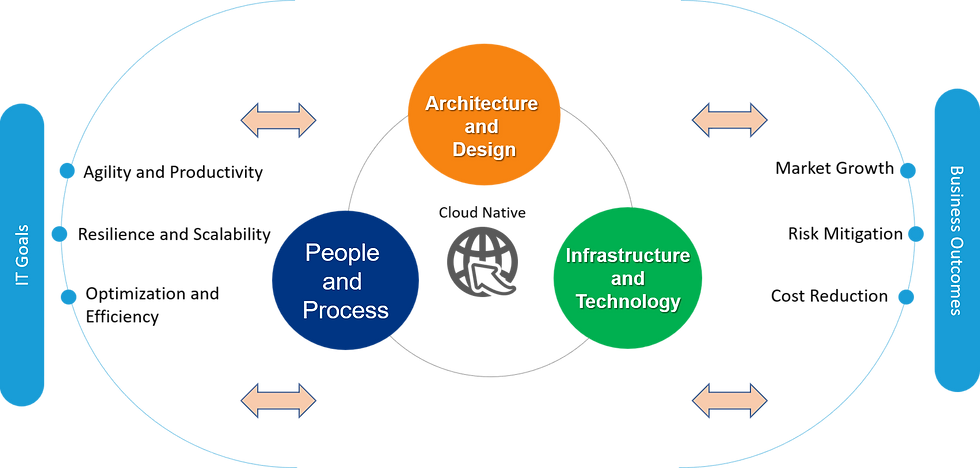
Technology alone cannot attain business outcomes.
In this article series, I will show how success in cloud-native relates to the coordination of changes across these three key areas to be coordinated to succeed: architecture & design, technology and infrastructure, people & process. Let’s explore each of these in more detail.
Technology & infrastructure: What is “cloud” in the context of “cloud-native”?
A decade or more ago, the term “cloud” was mainly about location. It usually referred to infrastructure located in someone else’s data center accessible over the internet. However, today “cloud” is more a statement about how you interact with that infrastructure. Indeed the location element has all but disappeared as it is now common to have a cloud-like facility that runs on in your data center — a “private cloud” as well as hybrid solutions that may involve services and workloads running across both.
So cloud today is more about how you engage with the infrastructure, which at a minimum must provide the following:
Self-provisioning: Requisition of new virtual resources (servers, storage, networking) instantly.
Elasticity: Automatically scale resources (and their associated costs) up and down based on demand.
Auto-recovery: Resources are designed to recover from failures without intervention and have minimal impact on service availability.
However, as cloud platforms and concepts have matured, the cloud in cloud-native also implies a greater abstraction from the underlying infrastructure.
Immutable deployment — e.g., container image-based deployment
Declarative provisioning — “infrastructure as code” providing a to-be state
Runtime agnostic — The platform sees components (e.g., containers) as black boxes, with no need to understand their contents.
Component orchestration — Enable management (monitoring, scaling, availability, routing etc.) through generic declarative policy and provisioning.
In the early years of cloud-native, these capabilities were typically highly proprietary. Still, now this comes almost ubiquitously in the form of containers and container orchestration capabilities such as Kubernetes. The above list is quite specific to the vocabulary of containers. Still, it’s worth recognizing that there are other options such as serverless/function as a service that further abstract from the infrastructure and will likely become more prominent in the future.
We could include more, such as build automation, service mesh, logging, tracing, analytics, software-defined networking and storage, etc. However, we would then be stepping into what are currently more proprietary aspects of cloud platforms. Hopefully, over time these too will become more standardized. So “cloud” in this context means infrastructure and technology with the unique properties listed above.
Architecture and Design: What do we mean by “native” in “cloud-native”?
By “native,” we mean that we will build solutions that don’t just “run on the cloud” but specifically leverage the uniqueness of cloud platforms. Applications don’t just magically inherit the benefits of the underlying cloud infrastructure; they have to be taught how.
We need to be careful with language here. When we use “native” to refer to the “uniqueness of cloud platforms,” we do not mean vendor-specific aspects of specific cloud providers. That would be “cloud provider native,” and indeed, that would go entirely against objectives around portability and the use of open standards. What we mean is the things that are conceptually common to all cloud platforms. In other words, the things we highlighted in the preceding section on infrastructure and technology.
There are important implications for architecture and design. We need to write our solutions to ensure, for example, that they can scale horizontally and that they can work with the auto-recovery mechanism. It is here that cloud-native perhaps overlaps most with microservices concepts. Which includes, for example, writing components that:
Minimize statefulness,
Reduce dependencies,
Have well-defined interfaces,
Are lightweight,
Are disposable
Perhaps the most important thing to note is that they are all highly interdependent. It is much harder, for example, to create a component that is disposable if it is highly stateful. Reducing dependencies will inherently help to make a feature more lightweight. Having well-defined interfaces will enable a disposable element to be more easily instantiated, and so on. This is a small example of the broader point that moving to a cloud-native approach requires changes on many related fronts simultaneously. These cloud-native ingredients we are gradually uncovering are mutually reinforcing.
People and Process: How does “cloud-native” change the way we organize and work?
What may be less obvious is that when we work with the above assumptions and decisions about the architecture and underlying infrastructure, it provides us opportunities to change the way we handle people and processes radically. Indeed it could be argued that it necessitates those changes.
Below I have explored some of the people/process implications resulting from a microservices approach:
Microservices implies that you are building your services in small, autonomous teams. This is simply the application of Conway’s Law — if you want your system to be composed of small, decoupled components, then you have to allow your teams to be small and not tightly coupled to other teams — only allowing formal communication through well defined and governed interfaces.
Microservices also implies that you are using agile methods and applying DevOps principles to your development processes. How will you gain the end-to-end feedback and rapid iterations on code that are a core benefit of the approach? DevOps, in turn, would imply further process improvements such as continuous integration and continuous delivery/deployment (CI/CD).
DevOps requires you to adopt other specific technical processes such as automated testing (perhaps including test-driven development), and strongly leads you toward trunk-based development. The desire to minimize testing cycles might further lead you to explore changing the way you align people to work (e.g., Pair Programming).
Likewise, there is an effect of container technology on required skill sets, roles, and processes:
The cloud infrastructure generally enables more to be achieved operationally (deployment, scaling, high availability etc.) using generic cloud platform skills such as knowledge of Kubernetes, rather than specific runtime or product skills. This radically reduces the learning curve for people working across multiple technology areas and enabling broader roles and knowledge sharing, increasing efficiency and reducing cost. It also encourages the shift to site reliability engineers to automate operational tasks wherever possible.
Containers and specifically container image technology simplify the automation of CI/CD pipelines, leading to shorter build/release cycle time and increasing productivity. The increased homogeneity of how build pipelines are achieved means they can be more easily maintained and used by a broader set of people.
Immutable container images combined with declarative “infrastructure as code” increase deployment consistency across different environments. This reduces testing and diagnostics costs, improves the speed of deployment, and reduces downtime. From a process perspective, this enables a “shift left” of aspects such as reliability, performance and security testing. This, in turn, enables a more DevOps/DevSecOps culture, where developers have more accountability for the operational qualities of the code.
Summarizing what it means to be “cloud-native.”
Bringing together what I have discussed so far, we can see that cloud-native needs to be defined from three aspects.
Platforms that abstract complexities of the infrastructure. (Infrastructure and Technology)
Solutions that make the best use of the infrastructure abstractions (Architecture and Design)
Automation of development, operations and business processes, and increasing autonomy of development teams (People and Process)
Today the technology aspect is, of course, heavily focused on containerization. Still, it is the properties such as self-provisioning, elasticity, and auto-recovery of that technology that is important, not the technology itself.
Architecturally we most commonly look to microservices principles to create more lightweight, fine-grained, state minimized components that map better to abstracted infrastructure. Without the right design principles, our solution will not benefit from the platform. For example, it will not dynamically scale or offer granular resilience, offer rapid build and deployment, or have operational consistency with other applications on the platform.
People and process changes are often seen as separate from cloud-native, but they go hand in hand with reality, and we consider them part of the defining characteristics. Lack of automation of the software development life cycle will mean a team spends more time on the mundane and comparatively little time on business value. A heavy, top-down organizational and governance structure will not provide teams the autonomy they need to help the business innovate.
So, with a more concrete definition of what cloud-native means, we’re ready to take the next step and expand out our previous diagram.
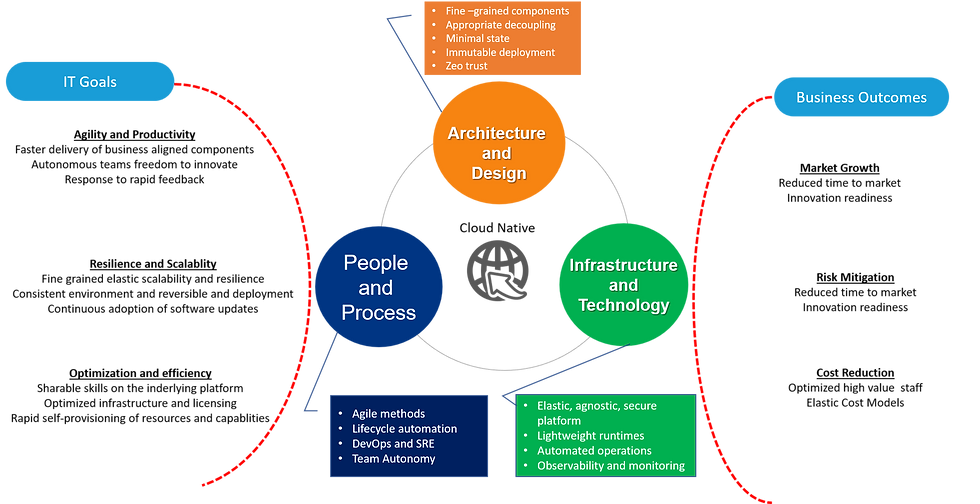
In the diagram above, I provide some teasers as to what the key ingredients are in each of these aspects. In the subsequent section of this article, I will consider “How” you go about building cloud-native solutions and look into each of those ingredients in detail, starting with people and process issues.
However, it should already be clear that to go fully cloud-native is non-trivial and requires business sponsorship.
The "How" of Cloud-Native: People and Process Perspective
In the previous section, where we discussed what cloud-native actually means, we established that to achieve the desired benefits from a cloud-native approach, you needed to look at it from multiple perspectives. It is about what technology you use and where your infrastructure is located, and how you architect your solutions. But perhaps most importantly, it is about how you organize your people and what processes you follow. In this and the next two section, I will walk through what I have seen to be the most important ingredients of successful cloud-native initiatives, taking a different perspective on each.
A summary of the themes in this series is shown in the diagram below:
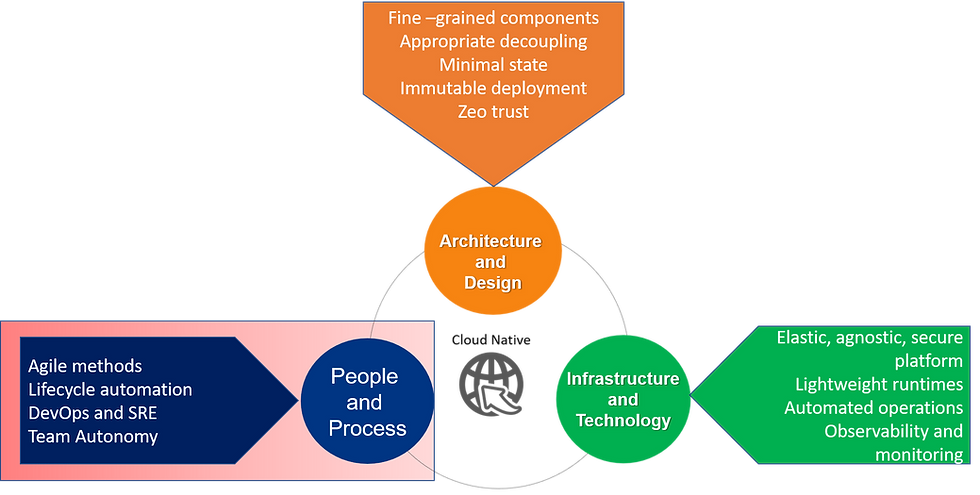
Let's begin by looking at perhaps the most overlooked perspective — how cloud-native affects the people involved and the processes they are part of.
The people and process ingredients of cloud-native
The people component outweighs any of the other parts in getting to cloud-native success. To achieve the business value of cloud-native, teams need to rapidly coordinate between business and IT, have a "low touch" way of getting their changes through to production, and be passionately accountable for what they deliver. No amount of new technology or modern architecture approaches will accomplish this on their own. Teams need to invest in moving to agile methods, adopt DevOps principles and software lifecycle automation, adopt new roles (such as SREs), and organizations must give teams an appropriate level of autonomy.
Some of the most critical people aspects of cloud-native in the diagram below:

The People and Process Ingredients of Cloud Native
This list is by no means complete. We would also assert that other people-based aspects improve team resiliency and cut across all the ingredients below, such as moving to a no-blame culture and encouraging a growth mindset. In the following sections, we'll dive into each of the elements in the above diagram in depth.
Agile methods
Cloud-native infrastructure and microservices-based design enable the development of fine-grained components that can be rapidly changed and deployed. However, this would be pointless if we did not have developed methods to leverage and deliver on that promise. Agile methods enable empowered (decentralized) teams to achieve rapid change cycles that are more closely aligned with business needs. They are characterized by the following:
Short, regular iteration cycles
Intrinsic business collaboration
Data-driven feedback
Agile methods are usually contrasted with older, "waterfall" methodologies. In a traditional waterfall method, all requirements are gathered upfront, and then the implementation team works in near isolation until they deliver the final product for acceptance. Although this method enables the implementation team to work with minimal hindrance from change requests, in today's rapidly changing business environment, the final delivery is likely to be out of sync with the current business needs.
Agile methodologies use iterative development cycles, regular engagement with the business, and meaningful data from consumer usage to ensure that projects stay focused on the business goals. The aim is to constantly correct the course of the project as measured against real business needs.
Work is broken up into relatively small business-relevant features that can then be prioritized more directly by the business for each release cycle. The real benefit to the enterprise comes when they accept that there cannot be a precise plan for what will be delivered over the long term but that they can prioritize what is built next.
Agile is becoming an "old" term and has suffered over time, as many words do, from nearly two decades of misuse. However, for the moment, is it perhaps still the most encompassing term we have for these approaches.
Lifecycle automation
You cannot achieve the level of agility that you want unless you reduce the time it takes to move new code into production. It does not matter how agile your methods are or how lightweight you have designed your components if the lifecycle processes are slow. Furthermore, if your feedback cycle is broken, you cannot react to changes in business needs in real-time. Life cycle automation is centered around three key pipelines.
These are:
Continuous Integration — Build/test pipeline automation
Continuous Delivery/Deployment — Deploy, verify
Continuous Adoption — Runtime currency (evergreening)
Interaction of these in the diagram below:

pipeline automation (CI/CD) is the fundamental groundwork for DevOps and agile methods
Continuous Integration (CI) means that as changes that are committed to the source code repository often ("continuously") and that they are instantly and automatically built, quality checked, integrated with dependent code, and tested. CI provides developers with instant feedback on whether their changes are compatible with the current codebase. We have found that Image-based deployment enables simpler and more consistent build pipelines. Furthermore, the creation of more modular, fine-grained, decoupled, and stateless components simplifies testing automation.
CD either stands for Continuous Delivery or Continuous Deployment. Continuous delivery takes the output from CI and performs all the preparation necessary for it to be deployed into the target environment. Still, it does not deploy it, leaving this final step manually in controlled, approved conditions. When an environment allows the automation to deploy into the environment, that is Continuous Deployment, with advantages in agility balanced against potential risks.
Continuous Adoption (CA) is a less well-known term for an increasingly common concept; keeping up to date with the underlying software runtimes and tools. This includes platforms such as Kubernetes, language runtimes and more. Most vendors and open source communities have moved to quarterly or even monthly upgrades. And they are failing to keep up with current software results in stale applications that are harder to change and support. Security updates, as a minimum, are often mandated by internal governance. Vendors can provide support for a minimal number of back versions, so support windows are getting shorter all the time. Kubernetes, for example, is released every three months, and only the most recent three are supported by the community. CI/CD, as noted above, means code changes trigger builds and potentially deployment. Enterprises should automate similar CA pipelines that are triggered when vendors or communities release new upgrades
It's worth noting that lifecycle automation is only as good as the efficiency of the processes that surround it. There's no value in working to bring your CI/CD cycle time down to minutes if your approval cycle for a release still takes weeks, or you are tied to a dependency that has a lifecycle measured in months.
DevOps and Site Reliability Engineering
As we can see from the figure above, lifecycle automation lays the groundwork for a more profound change to the way people work. As we simplify the mechanism between completion of code and its deployment into production, we reduce the distance between the developer and the operations role, perhaps even combining them.
This is known as DevOps and has some key themes:
Collaboration and combination across development and operations roles
"Shift left" of operational concerns
Rapid operational feedback and resolution
In traditional environments, there is a strong separation between development and operations roles. Developers are not allowed near the production environment, and operations staff have little exposure to the process of software development. This can mean that code is not written with the realities of production environments in mind. The separation is compounded when operations teams, to protect their environments, independently attempt to introduce quality gates that further impede the path to production, and cyclically the gap increases.
DevOps takes the approach that we should constantly strive to reduce and possibly remove the gap between development and operations to become aligned in their objective. This encourages developers to "shift left" many of the operational considerations. In practice, this comes down to asking a series of questions and then acting on the answers:
How similar can we make a development environment to that of production?
Can we test for scalability, availability, and observability as part of the earliest tests?
Can we put security in place from the beginning and not just switch it on at the end for major environments?
Platforms elements such as containers and Kubernetes can play an important role in this, as we will see from concepts such as image-based deployment and infrastructure as code that we will discuss later.
Clearly, the shortening of the path between development and production by using CI/CD is linked to DevOps, as is the iterative- and business-focused nature of agile methods. It also means changing the type of work that people do. Software developers should play an active role in looking after production systems rather than just creating new functions. The operations staff should focus on ways to automate monotonous tasks to move on to higher-value activities, such as creating more autonomically self-healing environments. When these two are combined, this particular role is often referred to as a Site Reliability Engineer to highlight the fact that they too are software engineers. The key to succeeding with this is the need to accept that "failures are normal" in components and that we should therefore plan for how to manage failure rather than fruitlessly try to stop it from ever happening.
In a perfect world, software development and operations become one team, and each member of that team performs both development and operations roles interchangeably. The reality for most organizations has some level of compromise on this, however, and parts still tend to become somewhat polarized toward one end of the spectrum or the other.
Team Autonomy
If we make the methods more agile and the path to production more automated, we must no then stifle their ability to be productive and innovative. Each team is tackling a unique problem, and it will be better suited to particular languages and ways of working. We should give the teams as much autonomy as possible through:
Decentralized ownership
Technological freedom
Self-provisioning
If we're going to iterate over more fine-grained components rapidly, we need to decentralize "one-size-fits-all" policies and allow more local decision-making. As discussed later, a good cloud platform should naturally encourage standardization around build, deployment and operations, so long as components are delivered consistently (e.g., container images). To be productive, teams then need to have freedom over implementing those components, choosing their own technologies such as languages and frameworks. Equally important is to ensure the teams can rapidly self-provision the tools and resources they need, which of course, aligns well with the very nature of cloud infrastructure.
There is still a need for a level of consistency in approach and technology across the enterprise. Approaches like the Spotify model, for example, often approach this need through "guilds", groups made from individuals from the teams that focus on encouraging (rather than enforcing) common approaches and tools based on real-world experiences in their own teams.
Of course, a caveat is that decentralization of control can't typically be ubiquitously applied, nor can it be applied all at once. It might make sense for only certain parts of an enterprise or certain types of initiatives in an enterprise. Ultimately, seek a balance between enabling elements of a company to innovate and explore to retain market leadership and ensure that you do not compromise the integrity of the core competencies of the business with constant change and increasing divergence.
Let’s look at what architecture and design choices we need to make to best leverage the cloud environment. In the meantime,
The "How" of Cloud-Native: Architecture and Design Perspective
In our previous section of this article, we discussed how a move to a cloud-native approach might affect how you organize your people and streamline your processes. In this section, we will drill down on how it relates to architecture and design principles.
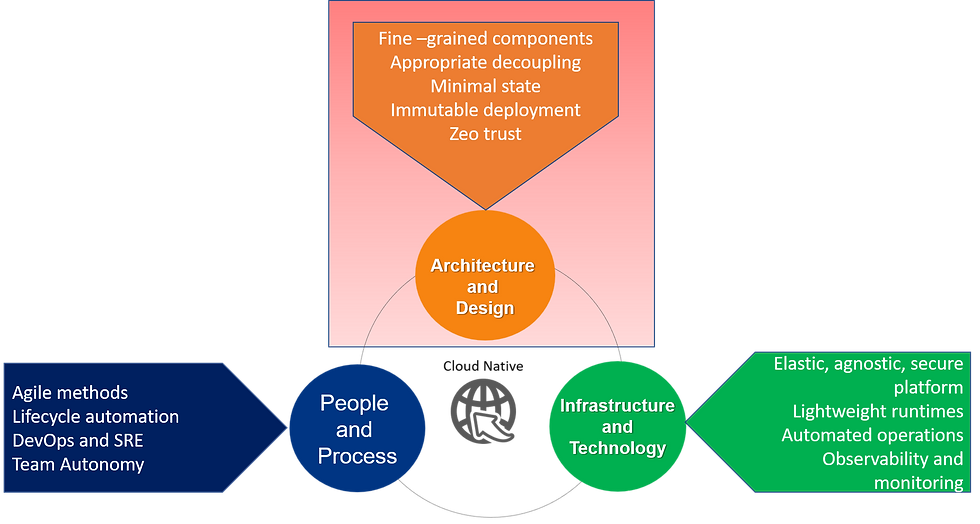
Ingredients of cloud-native — Architecture and Design
It is the architectural approach that brings the technology to life. It is possible to deploy traditional, siloed, stateful, coarse-grained application components onto the modern container-based cloud infrastructure. For some, that's a way to start getting their feet wet with clouds, but it should only be a start. If you do so, you will experience hardly any of the advantages of cloud-native. In this section, we will consider how to design an application such that it has the opportunity to leverage the underlying cloud infrastructure fully. It should quickly become apparent how well-decoupled components, rolled out using immutable deployments, is just as essential as embracing the agile methods and processes discussed already.
We show the pieces of cloud-native architecture below:
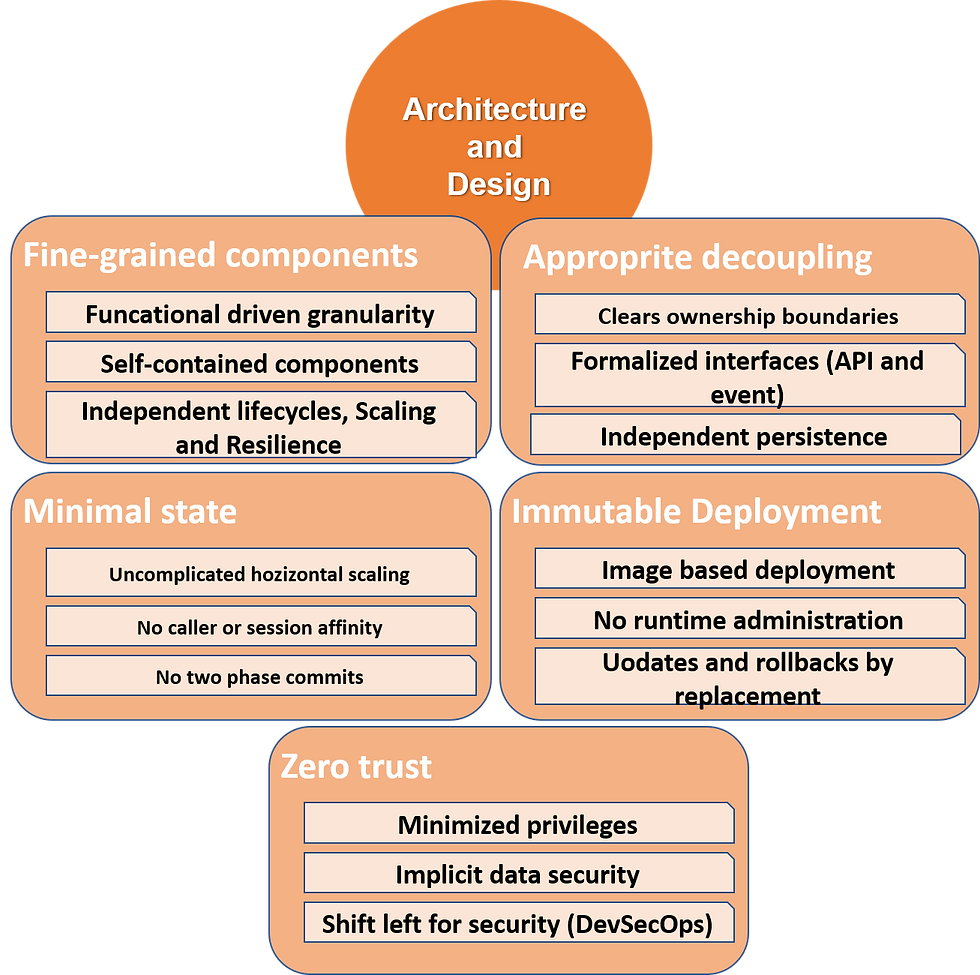
Components of Cloud Native Architecture
Fine-grained components
Until relatively recently, it was necessary to build and run software in large blocks of code to use hardware and software resources efficiently. More recent developments in technology, such as containers, have made it realistic to break up applications into smaller pieces and run them individually. There are a few different aspects to what we mean by fine-grained:
Function driven granularity — each component performs a single well-defined task
Self-contained components — the component includes all of its dependencies where possible
Independent lifecycles, scaling and resilience — The component is built from a single code repository through a dedicated pipeline and managed independently.
When building applications in this way, this is typically known as microservices, although it should be noted that an authentic "microservices approach" is much broader than just fine-grained components and indeed overlaps significantly with the concepts of cloud-native described here.
The core benefits of more fine-grained components are:
Greater agility: They are small enough to be understood entirely in isolation and changed independently.
Elastic scalability: Each component can be scaled individually, maximizing the efficiencies of cloud-native infrastructure.
Discrete resilience: With suitable decoupling, instabilities in one microservice do not affect others at run time.
While what is above can provide dramatic benefits in the right circumstances, designing highly distributed systems is non-trivial and managing them even more so. Sizing your microservice components is a deep topic in itself, and then there are other design decisions around just how decoupled they should be and how you manage versioning of the coupling that remains. Spotting necessary cohesion is just as important as introducing appropriate decoupling, and it is common to encounter projects that have gone too fine-grained and have had to pull back. In short, your microservices application is only as agile and scalable as your design is good and your methods and processes are mature.
Appropriate decoupling
Many of the benefits of fine-grained components (agility, scalability, resilience) are lost if they are not decoupled from one another. They need to have:
Clear ownership boundaries
Formalized interfaces (API and event/message)
Independent persistence
Writing modular software is hardly new. From functional decomposition through object-oriented programming to service-oriented architecture, all design methodologies have aimed to break up significant problems into smaller, more manageable pieces. The opportunity in the cloud-native space is that we can run each as a genuinely independent component by taking advantage of technologies such as containers. Each member has its CPU, memory, file storage, and network connections as if it were an entire operating system. Therefore, it is only accessible over the network, which creates an apparent and enforceable separation between components. However, the decoupling provided by the underlying platform is only part of the story.
From an organizational point of view, ownership needs to be precise. Each component needs to be owned entirely by a single team that has control over its implementation. That's not to say that teams shouldn't accept requests for change and pull requests from other teams, but they control what and when to merge. This is key to agility since it ensures the team can feel confident in making and deploying changes within their component so long as they respect their interfaces with others. Of course, even then, couples should work within architectural boundaries set by the organization as a whole, but they should have considerable freedom within those boundaries.
Components should explicitly declare how you can interface with them, and all other access should be locked down. They should only use mature, standard protocols. Synchronous communication is the simplest, and HTTP's ubiquity makes it an obvious choice. More specifically, we typically see RESTful APIs using JSON payloads, although other protocols such as gRPC can be used for specific requirements.
It is essential to differentiate between calls across components within the same ownership boundary (e.g., application boundary) and calls to elements in another ownership boundary.
However, the synchronous nature of HTTP APIs binds the caller to the availability and performance of the downstream component. Asynchronous communication through events and messages, using a "store and forward" or "publish/subscribe" pattern, can more completely decouple themselves from other components.
A typical asynchronous pattern is that data owners publish events about changes to their data (creates, updates, and deletes). Other components that need that data listen to the event stream and build their local datastore so that when they need the data, they have a copy.
Although asynchronous patterns can improve availability and performance, they do have an inevitable downside: They result in various forms of eventual consistency, which can make design, implementation, and even problem diagnosis more complex. The use of event-based and message-based communication should therefore be suitably qualified.
Minimal state
Clear separation of the state within the components of a cloud-native solution is critical. Three key common topics come up:
Uncomplicated horizontal scaling
No caller or session affinity
No two-phase commits across components
Statelessness enables the orchestrating platform to manage the components optimally, adding and removing replicas as required. Statelessness means there should be no changes to the configuration or the data held by an element after it starts that makes it different from any other replica.
Affinity is one of the most common issues. They were expecting a specific user or consumer's requests to return to the same component on their following invocation, perhaps due to particular data caching. Suddenly, the orchestration platform can do simple load-balanced routing, relocation, or scaling of the replicas.
Two-phase commit transactions across components should also be ruled out, as the semantics of the REST and Event-based protocols do not allow the communication of standardized transaction coordination. The independence of each fine-grained component, with its minimal state, makes the coupling required for a 2PC coordination problematic in any case. As a result, alternative ways of handling distributed updates, such as the Saga pattern, must be used, considering eventual consistency issues already alluded to.
Note that this concept of a minimal state should not be confused with a component interacting with a downstream system that holds a state. For example, a member might interact with a database or a remote message queue that persists state. However, that does not make our component stateful, and it is just passing stateful requests onto a downstream system.
There will always be some components that require state. Platforms such as Kubernetes (K8s) have mechanisms for handling stateful components with extra features and associated restrictions. The point is to minimize it and to declare and manage it when it does occur.
Immutable deployment
If we are to hand over control to a cloud platform to deploy and manage our components, we need to make it as straightforward as possible. In short, we want to ensure there is only one way to deploy the component, and once deployed, it cannot be changed. This is known as immutable deployment and is characterized by the following three principles
Image-based deployment — We deploy a fixed "image" that contains all dependencies
No runtime administration — No changes are made directly to the runtime once deployed
Updates and rollbacks by replacement — Changes are performed by deploying a new version of the component's image.
From "appropriate decoupling," we already know that our components should be self-contained. We need a way to package up our code and all its dependencies to enable remarkably consistent deployment. Languages have always had mechanisms to build their code into a fixed "executable," so that's not new. Containers bring us the opportunity to go a step further than that and package up that code/executable along with the specific version of the language runtime and even the relevant aspects of the operating system into a fixed "image." We can also include security configuration such as what ports to make available and critical metadata such as what process to run on startup.
This allows us to deploy into any environment consistently. Development, test, and production will all have the same full-stack configuration. Each replica in a cluster will be provably identical. The container image is a fixed black box and can be deployed to any environment, in any location, and (in an ideal world) on any container platform and will still behave the same.
Once started, the image must not be further configured at runtime to ensure its ongoing consistency. This means no patches to the operating system, no new versions of the language runtime, and no new code. If you want to change any of those things, you must build a new image, deploy it, and phase out the original image. This ensures we are confident of what is deployed to an environment at any given time. It also provides us with an effortless way of rolling back any of these types of change. Since we still have the preceding image, we can simply re-deploy it — assuming, of course, that you adhered to "minimal state."
Traditional environments were built in advance, before deployment of any code, and then maintained over time by running commands against them at runtime. It's easy to see how this approach could often result in configuration divergence between environments. The immutable deployment approach ensures that code is always deployed hand-in-hand with its own copy of all the dependencies and configuration it was tested against. This improves testing confidence, enables simpler re-creation of environments for functional, performance and diagnostics testing, and contributes to the simplicity of elastic scaling.
Note that in theory, we could have done image-based deployment with virtual machine images, but they would have been unmanageably large. It was thus more efficient to run multiple components on a virtual machine instance, which meant there was no longer a one-to-one relationship between the code and its dependencies.
Zero trust
Put simply, and zero trusts assumes that all threats could potentially occur. Threat modeling has a long history, but the nature of cloud-native solutions forces us to reconsider those threats and how to protect against them. Some (but not all) of the key tenets for a zero-trust approach are:
Minimal privileges — Components and people should have no privileges by default. All privileges are explicitly bestowed based on identity.
Implicit data security — Data should always be safe, whether at rest or in transit.
Shift Left security (DevSecOps) — Security should be included at the earliest possible point in the lifecycle.
It has long been known that traditional firewall-based access control results in inappropriate trust of the internal network. Indeed the assumption that you can create trusted zones in a network is, at best, only a first line of defense. Identity needs to become the new perimeter. We should aim for fine-grained access control based on the identity of what we are trying to protect: users, devices, application components, data. Based on these identities, we should then offer only the least amount of privileges. Connectivity between components should be explicitly declared and secured (encrypted) by default. Administrators should only be given the special rights they need to perform their roles. We must also regularly perform vulnerability testing to ensure that there are no paths to permissions escalation.
Applications must accept that they have a responsibility to keep their user's data safe at all times. There are ever more sophisticated ways to correlate data from multiple sources, deriving new information for malicious purposes. Applications should consider the privacy of all data they store, encrypt any sensitive data both at rest and in transit, and ensure it is only accessible by identities with explicit permission.
Application components must be built secure from the start. We must assume that all environments, not just production, are vulnerable to attack. But more than that, through a "shift left" of security concerns, we should ensure that application designers collaborate early on with the security team and embed secure practices seamlessly for example, in build and deploy pipelines. This further improves the speed, consistency, and confidence to deliver code to production continuously.
The "How" of Cloud-Native: Technology and Infrastructure Perspective
While the people, process, architecture and design issues we covered in the last two sections are all critical enablers for cloud-native, cloud-native solutions ultimately sit upon technology and infrastructure, which is what we're going to cover in this article.

Ingredients of cloud-native — Technology and Infrastructure
Cloud infrastructure is all about abstracting away the underlying hardware to enable solutions to be rapidly self-provisioned and scaled. It should allow the administration of different language and product runtimes using the same operational skills. Furthermore, it should promote the automation of operations and provide a framework for observability. Let's take a closer look at exactly what the key characteristics of that infrastructure are leveraged in a cloud-native approach.
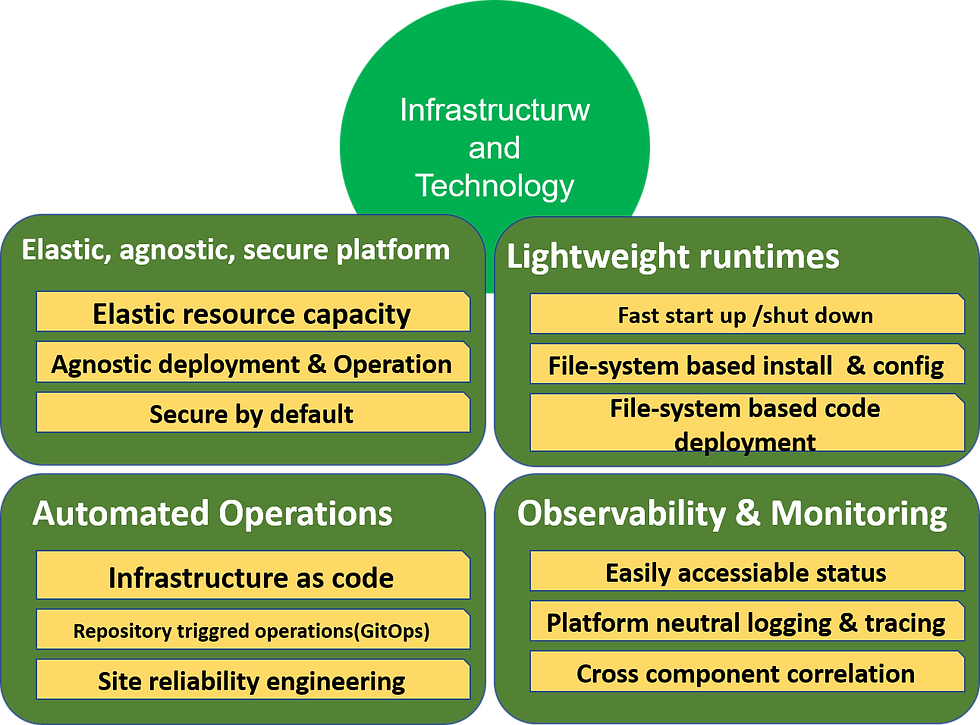
Technology and Infrastructure aspects of cloud-native
Elastic, agnostic, secure platform
For cloud-native to work, we have to ask a lot from the platform on which we deploy our components. The platform should help us not to worry about nonfunctional concerns by using common mechanisms across whatever we deploy and likewise should "burn-in" security. Therefore, our top requests from the platform should be:
Elastic resource capacity
Agnostic deployment and operations
Secure by default
If developers are to increase their productivity, they need to focus purely on writing code that creates business value. That means the platform should take care of load balancing, high availability, scalability, resilience, and even some elements of disaster recovery. At deployment, we should specify high-level nonfunctional requirements and let the platform do the rest. We will use Kubernetes container orchestration as a powerful (indeed ubiquitous) example of this kind of thinking, but cloud-native is definitely not limited to the Kubernetes platform.
A Kubernetes cluster provides automated, elastic provisioning of resources such as CPU, memory, storage and networking based on the component's requirements being deployed. The pool of resources can be spread across many physical machines and over multiple availability zones in many separate regions. It takes on the responsibility of finding the resources you need and deploying your components to them. You only need to specify your requirements — what resources you need, how they should or should not be spread out, and how they should be scaled and upgraded. Arguably, we could also have said that about platforms based on virtual machines, but as we will see, containers bring something more to the party.
Assuming we adhere to the architectural principles from the previous section, delivering application components in containers enables Kubernetes to perform deployment and subsequent operations in a standardized way, regardless of the contents of any given containers. The components are largely stateless, disposable, fine-grained, and well-decoupled; this makes it easy for the platform to deploy, scale, monitor, and commonly upgrade them without knowing their internals. Standards like Kubernetes are part of a trend of gradually moving away from proprietary installation and topology configuration for each software product. They all work the same way, and we benefit from operational consistency, reduced learning curves, and broader applicability of add-on capabilities such as monitoring and performance management.
Finally, we want to have security burnt into the platform to be confident it is a safe environment for our applications from day one. We should not need to re-engineer core security aspects every time we design a new component; we should instead inherit a model from the platform. Ideally, this should cover identity management, role-based access to administration, securing external access and internal communications. We will note that this is an example where Kubernetes itself is only a partial solution; added elements such as a service mesh for internal communication and ingress controllers for inbound traffic are also required for a complete security solution.
Lightweight runtimes
We can only achieve operational agility if the components are as straightforward and lightweight as possible. We can boil this down into three main properties.
Fast startup/shut down
Filesystem based install and configuration
File-system based code deployment
To manage availability and scaling, components must be able to be rapidly created and destroyed. That means the runtimes inside the containers must start up and shut down gracefully and optimally. They must also be able to cope with ungraceful shutdowns. There are many possible optimizations this implies: from removing dependencies, reducing memory population performed during initiation, through enabling a "shift left" of compilations into the image build. At a minimum, runtimes should start within the order of seconds, but that expectation is constantly lowering.
We also want to be as straightforward and timely as possible if we are to embrace continuous integration. Most modern runtimes have removed the need for separate installation software, instead simply allowing files to be laid down on a file system. Similarly, since an immutable image by definition shouldn't be changed at runtime, they typically read their configuration from properties files rather than receiving them through custom runtime commands.
Equally, your actual application code can also be placed on the filesystem rather than deployed at runtime. Combining these features enables it to be done rapidly through simple file copies and is well suited to the layered filesystem of container images.
Automated operations
What if we could deliver the entire blueprint for setting up our solution at runtime — including all aspects of infrastructure and topology — as part of the release? What if we could store that blueprint in a code repository and trigger updates with our application code? What if we could laser-focus the role of operations staff into making the environment autonomous and self-healing? These questions lead to some critical ways in which we should approach the way we work with infrastructure differently:
Infrastructure as code
Repository triggered operations (GitOps)
Site reliability engineering
Image-based deployment, as discussed earlier, has already brought us a long way toward ensuring greater consistency. However, that only delivers the code and its runtime. We also need to consider how the solution is deployed, scaled and maintained. Ideally, we want to provide this all as "code" alongside our component's source to ensure that it is built consistently across environments.
The term "infrastructure as code" initially focused on low-level scripting infrastructures such as virtual machines, networking, storage and more. Scripting infrastructure isn't new, but increasingly specific tools such as Chef, Puppet, Ansible, and Terraform have advanced the possible art. These tools begin with the assumption that there is available hardware and the provision and then configure virtual machines upon it. What is interesting is how this picture changes when we move to a container platform.
In a perfect world, our application should assume that there is, for example, a Kubernetes cluster already available. That cluster might have been built using Terraform, but that is irrelevant to our application; we just assume the cluster is available. So what infrastructure as code elements do we need to provide to specify our application now fully? Arguably, that would be the various Kubernetes deployment definition files packaged in helm charts or Kubernetes Operators and their associated Customer Resource Definition (CRD) files. The result is the same — a set of files that can be delivered with our immutable images that describe entirely how it should be deployed, run, scaled and maintained.
So if our infrastructure is now code, then why not build and maintain our infrastructure the same way as we make our application? Each time we commit a significant change to the infrastructure, we can trigger a "build" that deploys that change out to environments automatically. This increasingly popular approach has become known as GitOps. It's worth noting that this strongly favors infrastructure tools that take a "declarative" rather than "imperative" approach. You effectively provide a properties file that describes a "to-be" target state; then, the tooling works out how to get you there. Many of the tools mentioned above can work in this way, which is fundamental to how Kubernetes operates.
Real systems are complex and constantly changing, so it would be unreasonable to think that they will never break. No matter how good a platform like Kubernetes is at automating dynamic scaling and availability, issues will still arise that will at least initially require human intervention to diagnose and resolve. However, in the world of automated deployments of fine-grained, elastically scaled components, it will become increasingly impossible to sustain repeated manual interventions. These need to be automated wherever possible. To enable this, operations staff are being retrained as "site reliability engineers" (SREs) to write code that performs the necessary operations work. Indeed, some organizations are explicitly hiring or moving development staff into the operations team to ensure an engineering culture. Increasingly, providing the solution is self-healing means that we no longer have the problematic need for a corresponding increase in operations staff when the systems scale up.
Observability and monitoring
As organizations move towards more granular containerized workloads treating monitoring as an afterthought is untenable. This is yet another example where we need to "shift left" to be successful in cloud-native. Addressing the problem depends upon being able to answer three questions about our components:
Is it healthy? Does your app have an easily accessible status?
What's going on inside it? Does your app use platform-neutral logging and tracing effectively?
How is it interacting with other components? Do you take advantage of cross-component correlation?
Observability is not a new term, although it sees renewed use in IT and particularly around cloud-native solutions. Its definition comes from the ancient discipline of control theory. It is a measure of how well you can understand the internal state based on what you can see from the outside. If you are to be able to control something responsively, you need to observe it accurately.
Some definitions create a distinction that that monitoring is for your known unknowns, such as component status. In contrast, observability is for your unknown unknowns — finding answers to questions you hadn't thought to ask before. In a highly distributed system, you're going to need both.
The platform must be able to easily and instantly assess the health of the deployed components to make rapid lifecycle decisions. Kubernetes, for example, requests that components implement simple probes that report whether a container has started, is ready for work, and is healthy.
Additionally, the component should provide easily accessible logging and tracing output in a standard form based on its activity for both monitoring and diagnostics purposes. In containers, typically, we simply log to standard output. The platform can then generically collate and aggregate those logs and provide services to view and analyze them.
With fine-grained components, there is an increased likelihood that interaction will involve multiple components. To understand these interactions and diagnose problems, we will need to be able to visualize cross-component requests. An increasingly popular modern framework for distributed tracing that is well-suited to the container world is OpenTracing.
Looking back on the Perspectives
Based on what we've seen, these are the key ingredients across all the previously mentioned perspectives that are required to make cloud-native successful:

Ingredients of Cloud Native
They are often interrelated and typically mutually reinforcing. Do you need to do them all? That's probably the wrong way to phrase the question, as few if any of the above are a simple binary "yes you're doing it" or "no you're not." The question is more to what level of depth are you doing them. You certainly need to consider your status for each one and assess whether you need to go further.
The "Why" of Cloud-Native: Goals and Benefits
In our last section, we've established "what" cloud-native refers to and even "how" cloud-native works. However, there's a bigger, more fundamental question we haven't addressed. Why should anyone care? Given the background from the previous two articles, we can now explore the "why" and look at the benefits of cloud-native, starting at a high level of what it means to the business, then dropping down to what it means on the ground.
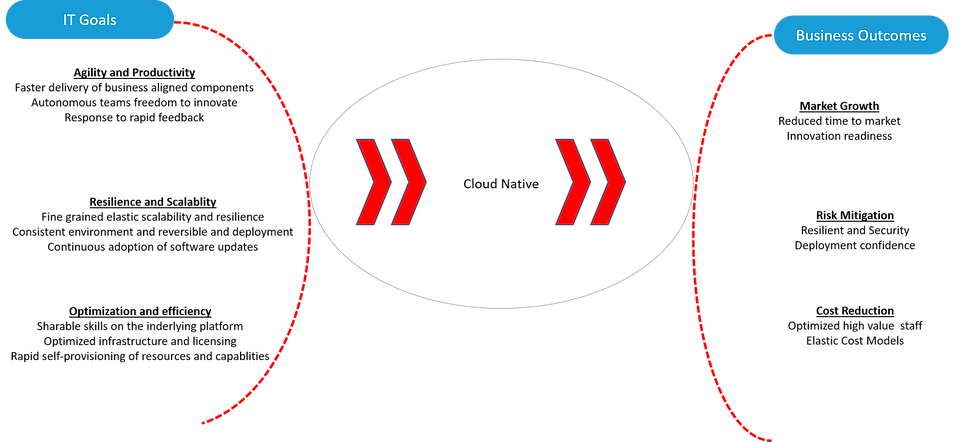
A business perspective on goals and benefits
Let's face it, IT fads come and go. Many business teams try to stay above those fads and let the IT folks go their own way. After all, the choice of an application server or language runtime usually doesn't have much bearing on how the business operates. What makes cloud-native any different? Why should the business support a move to cloud-native? To understand that, we need to start from the point of view, taking into account three key things nearly all businesses must focus on to be successful: growth, risk mitigation and cost reduction. We would argue that building applications with a cloud-native approach can provide benefits in all of these categories.
Market growth
Market growth is all about capturing new customers and keeping their interest. To win new customers and retain the interest of marginal customers, you have to bring good, new ideas to market faster than your competition. Adopting lean methods and streamlining the path to production through pipeline automation enable teams to bring business ideas to show more quickly. This enables a reduced time to market, helping IT to move at the speed of the business in bringing out new features. However, new features will not, by themselves, ensure market growth. You have to winnow out those new features that negatively affect customer retention and customer acquisition and allow those to die while keeping those new features that have a positive effect on those two measures. The real key is to ensure innovation readiness; letting the business boldly and rapidly bring disruptive ideas to life to capture new market niches ahead of the competition, while at the same time putting in place measurements that allow you to determine empirically which ideas were good, and which ideas were not good.
Risk mitigation
New features are not everything a business needs, however. If a business could just forge ahead by constantly delighting its customers with new, awesome features, then we would have an easier job. The reality is more complex and difficult, but no less important. Customers need to trust your business. This is, of course, most visible in highly regulated industries such as financial services or healthcare but relevant to every business. The solutions you provide need to have an appropriate degree of resilience and security to ensure that customers can be sure you'll be there when they need you, and they can trust you with their money, their data, or their lives.
Well-written cloud-native solutions use abstraction to decouple themselves from the underlying physical infrastructure, offering implicit resilience. Furthermore, they also follow a zero trust model for their components since they must assume portable deployment into any cloud environment. However, the more we are concerned with risk, the more likely we are to put up barriers to making changes, which works against our need for market growth. It is here that cloud natives can help in risk mitigation by providing highly automated and consistent ways to put things into production, reducing the fear of change through deployment confidence.
However, a cloud-native approach doesn't magically reduce risk on its own. Techniques like feature flags and canary testing can enable the business to do things that they might previously have rejected as risky, but that requires close cooperation with the business for those techniques to become valuable to the business. We must work with the business to update how they measure and control risk to be compatible with the methods and processes being introduced.
Cost reduction
No business can ignore cost. It doesn't matter how big your market share is or how much your customers trust you; if you can't control costs, you can't count on reliable profits. Businesses are run by people (at least today!), and people cost money. We need to ensure we can get the best from the smallest number of them, which is all the more true of those with the greatest skills. The platforms on which cloud-native solutions are built should aim to standardize and, wherever possible, automate the day-to-day tasks of building, deploying and managing software. This makes for optimized high-value staff who can directly add value to the business rather than getting bogged down with day-to-day operations. Of course, those platforms and their underlying infrastructure need to be paid for too. Fortunately, cloud-native solutions are designed to use only the resources they need, so you should take advantage of elastic cost models provided by the platform to enable you to take advantage of that cost-efficiency.
IT perspective on goals and benefits
To this point, our discussion has been a bit high-level in terms of how cloud-native impacts the business. To comprehend the benefits of cloud-native, we have to translate the IT benefits we have discussed into corresponding business benefits. We'll next show how each of the key business benefit areas above map to our earlier cloud-native ingredients.
Agility and productivity (Market growth)
Every business wants more features from IT — they also want them faster, and they want them to reflect what they need more accurately. How does cloud-native help with that?
Faster delivery of components
Delivery acceleration is of the most commonly stated goals for a cloud-native approach and pulls together three core aspects: cloud platforms, agile methods and microservices. Cloud platforms, through aspects such as elastic provisioning and component orchestration, enable us to focus on building business functionality by automating and simplifying most of the day-to-day operations work. By reducing toil, they allow teams to focus on higher-value work. Agile methods should shorten the distance between requirements and implementation and improve alignment with business goals. That means that less rework is required, and bad ideas are discovered and corrected more quickly. Design approaches such as microservices enable us to deliver functionality incrementally, with fewer dependencies, and thereby more rapidly.
Autonomous teams with the freedom to innovate
An intentional consequence of fine-grained and discrete components is that it offers more autonomy to the teams creating them. As long as the key rules of decoupling we earlier described are followed, the components can be treated largely as a "black box" by the receiving platform. While cross-team collaboration and common practices should be encouraged, teams are free to, for example, use whatever language runtimes and frameworks are most productive for their needs. This freedom to innovate allows teams to "think out of the box" and deliver solutions to the business more quickly and deliver solutions that are more innovative in terms of the business. A key aspect of this autonomy is that the business must be part of each autonomous team. The notions of a Product Owner and Sponsor Users are critical to building productive but innovative teams.
Responsive to changing business conditions
Earlier, we talked about how the ability to innovate and determine if innovation is valuable through concrete and empirical measurements were important to make the team ready to move at the speed of the business. A critical aspect of this is the ability of the business and IT to work together through Hypothesis-driven development. Simply put, Hypothesis Driven Development is phrasing business ideas as scientific hypotheses that can be either proven or dis-proven. Cloud-native development only brings benefit to the business if the business is engaged throughout the development cycle.
A primary form of engagement is through A/B testing. If you put a measurement in places, such as the percentage of abandoned carts, or the percentage of customers that click "buy" after browsing, you can compare different ideas empirically. You can direct some of your customers to a new approach featuring a new idea and others to the existing approach, and then compare the difference in the measurement between the two over time. The key here is that this requires the business to think in terms of measurable differences. Much as a scientific hypothesis isn't a hypothesis if it cannot be disproven, the same applies to a business hypothesis. The business has to help determine a quantifiable measure by which two different ideas or approaches can be compared. That means that they have to be involved throughout the process in helping determine not only what ideas should be tested, how they should be tested, and what the definition of success means. Cloud-native is well suited to enabling this responsive behavior. It is an essential part of agile methodology, and the use of fine-grained, well-decoupled components makes it safer to add new functionality without disturbing what's already there.
Furthermore, generic mechanisms such as a service mesh can be used to selectively route requests across the ideas being tested, as well as simplify the collection of data for hypothesis assessment.
Resilience and scalability (Risk mitigation)
Cloud platforms, and especially containers, inherit several abstractions from their underlying infrastructure. This enables common and lowers risk approaches to non-functional requirements such as availability, robustness, performance and security. Some key examples are:
Fine-grained elastic scalability and resilience
A well-written cloud-native solution is built with fine-grained, lightweight components with a minimized state. This enables the cloud platform to inherently provide robustness and scalability by rapid replication and disposal of components as required. Thanks to containerization, this can be provided in a standardized way, resulting in significant operational simplification. Furthermore, the ability for container orchestration platforms to distribute container instances across multiple physical servers over multiple regions further increases the level of resilience possible.
Consistent environments and reversible deployments
For the agility and productivity discussed in the earlier section to become a reality, we need to be able to deliver new code into environments confidently, safely re-route traffic and indeed reverse those deployments with minimal pain if necessary. Ideally, cloud-native code should be delivered in immutable images containing all dependencies and including complete, declarative deployment instructions. This ensures that the deployment process and artifacts are identical in all environments, eliminating the risk of environment drift. Furthermore, features of the cloud platform such as routers and service meshes enable the code to be canary tested (passing a small amount of load through the new code) before full rollout. This also simplifies rolling back a release, as we can simply revert to the images and deployment instructions of the previous release. This simplicity is important to the business, as it assures them that changes can be quickly and safely reversed if the outcome is not what was expected.
Continuous adoption of software runtimes
Agile methods dictate that the path to production must be as automated as possible in build, test and deployment. Often termed continuous integration/continuous delivery (CI/CD), these pipelines are typically triggered due to changes to the source code. However, since a declarative deployment is also code, a change to the version of an underlying runtime can also trigger a new build/test cycle — an example of "GitOps." Assuming sufficient confidence in our automated tests, this should enable us to keep underlying runtime versions much more current than most applications do today, ensuring not only that we can capitalize on the latest features but also that we are not at risk from known security vulnerabilities. Again, this should be valuable to the business in that it reduces the fiduciary risk of the loss of customer data or assets.
Optimization and efficiency (cost reduction)
Cloud-based computing enables us to pool resources: hardware, software, and indeed people too. By sharing these resources across applications, across domains in the organization, and even across organizations. we have the opportunity to reduce operational costs. Cloud-native ensures applications are written to gain the most from those optimizations.
Consistent skills on the underlying platform
Underlying the apparent characteristics of containers — lightweight scalable components — there is a much greater gem. Perhaps their most significant benefit over the long term is in operational consistency. Using precisely the same skills to build, deploy, provide high availability, scale, monitor, diagnose, and secure regardless of the runtimes within a set of orchestrated containers is a giant leap forward. At a minimum, this means transferable, standard skillsets across previously siloed parts of the IT landscape. At best, the opportunities for automation of operations should result in a reduction in the number of people required to run a given infrastructure and an increase in its reliability. However, since these technologies are new, there is a steep learning curve that individuals and companies must go through before these benefits become a reality.
Optimized infrastructure usage and licensing
Arguably the most fundamental definition of "cloud" is an abstraction from the underlying physical infrastructure. Virtual machines gave us the first level of indirection in that we were no longer tied to specific hardware within a physical device. Containers, if coupled with cloud-native ingredients such as minimal state, immutable deployment, etc., take us much further. Cloud-native enables us to invisibly distribute components across many machines in multiple data centers, providing more significant opportunities for economies of scale. Software licensing of course, needs to rise to this challenge with new models and potentially more sophisticated and dynamic metering.
Rapid self-provisioning of resources and capabilities
Self-provisioning is one of the key promises of the cloud, enabling rapid requisition of virtual compute, memory, storage, networking and more. Container platforms further abstract this by allowing declarative requests for resources at the point of deployment and setting policies for how these change at runtime based on load. Whole new environments can be created with a single click and segregated from other environments through software-defined networking. To make the most of all this, applications need to be written differently. Applications need to be stateless, disposable, fine-grained, and indeed, all of the things we have discussed in this series.
Conclusions
Cloud-native, just like most significant changes in approach, requires a level of commitment to achieve your goals. As we have seen, that requires many different ingredients to be in place. For many, perhaps most, organizations it may be impossible to get all of those ingredients in place from the start, so the key to success is prioritization.

Comments